

Tietokantojen suunnittelua
Suunnittelun periaatteet
Tietokannan suunnittelussa meidän tulee päättää tietokannan rakenne: mitä tauluja tietokannassa on sekä mitä sarakkeita kussakin taulussa on. Tähän on sinänsä suuri määrä mahdollisuuksia, mutta tuntemalla muutaman periaatteen pääsee pitkälle.
Hyvä tavoite suunnittelussa on, että tuloksena olevaa tietokantaa on mukavaa käyttää SQL-kielen avulla. Tietokannan rakenteen tulisi olla sellainen, että pystymme hakemaan ja muuttamaan tietoa näppärästi SQL-komennoilla.
Tässä ovat neljä tietokannan sunnittelun periaatetta:
Periaate 1
Taulut ja niiden sarakkeet ovat kiinteitä, ja tietokannan käyttäjä tekee muutoksia vain riveihin. Kaikki samanlaista tietoa sisältävät rivit ovat samassa taulussa.
Periaate 2
Jokainen sarake sisältää yksittäistä dataa, kuten kokonaisluvun tai tekstiä, mutta ei listaa asioista. Lista talletetaan omaksi taululukseen siten, että jokainen elementti on oma rivinsä.
Periaate 3
Jokainen tietue on tietokannassa tasan kerran. Muualla tähän tietoon viitataan pääavaimella.
Periaate 4
Tietokanta ei sisällä tietoa, joka voidaan laskea tai päätellä muusta tietokannan sisällöstä.
Esimerkki
Tarkastellaan tilannetta, jossa verkkosivulla on käyttäjiä ja jokaisella käyttäjällä on lista ystäviä. Tässä näemme melko huonosti suunnitellun taulun Users, joka sisältää tietoa käyttäjistä ja heidän ystävistään:
id username friends total---------- ---------- ------------ ----------1 uolevi maija,liisa 22 maija aapeli 13 liisa 04 aapeli uolevi,maija 2
Ajatuksena tässä taulussa on, että sarake friends sisältää listan ystävistä tekstinä, jossa ystävien käyttäjätunnukset (username) ovat eroteltu pilkuin. Lisäksi, sarakkeessa total on annettu ystävien kokonaismäärä.
Tällä rakenteella rikomme periaatteita 2-4, mutta nyt meillä on mahdollisuus parantaa tietokantaa ja pohtia, mihin periaatteet pohjautuvat.
Parannus 1
Tietokanta rikkoo periaatetta 2, sillä sarake friends sisältää listan ystävistä. Ongelmana tässä sarakkeessa on, että sitä on hankala käsitellä SQL-komennoilla. Esimerkiksi miten saamme selville, ketkä kaikki ovat lisänneet Maijan ystäväkseen?
Ratkaisuna on poistaa sarake friends ja luodaan uusi taulu Friends, jossa jokainen rivi on ystävyyssuhde muorossa "käyttäjällä X on käyttäjä Y kaverilistallaan":
user friend---------- ----------uolevi maijauolevi liisamaija aapeliaapeli uoleviaapeli maija
Nyt taulu Users näyttää tältä:
id username total---------- ---------- ----------1 uolevi 22 maija 13 liisa 04 aapeli 2
Nyt voimme helposti ratkaista, keiden listoilla Maija on:
SELECT user FROM Friends WHERE friend='maija';
Parannus 2
Uusi taulu Friends on hyvä, mutta se rikkoo periaatetta 3, sillä käyttäjänimet ovat nyt useassa paikassa. Ongelmana on, että käyttäjänimen muuttuessa, joudume etsimään kaikki paikat jossa käyttäjänimeä on käytetty.
Ratkaisuna on muuttaa taulu Friends käyttämään viitteitä. Nyt taulu näyttää tältä:
user_id friend_id----------- ----------1 21 32 44 14 2
Huomaa, tämän myötä on hankalampaa löytää keiden listoilla Maija on, koska joudumme hakemaan käyttäjänimet taulusta Users:
SELECT A.usernameFROM Users A, Users B, Friends KWHERE A.id = K.user_id AND B.id = K.friend_id AND B.username = 'maija';
Tästä huolimatta muutos on järkevä, sillä käyttäjänimiä käytetään nyt vain kerran, taulussa Users.
Parannus 3
Tietokanta rikkoo edelleen periaatetta 4, sillä sarake total pystytään laskemaan taulusta Friends. Se on oikein näppärä sarake, sillä tällä hetkellä voimme esimerkiksi hakea Uolevin ystävät seuraavasti:
SELECT total FROM Users WHERE username='uolevi';
Ongelmana tosin on, että joka kerta ystävien muuttuessa, meidän pitäisi päivittää myös saraketta total. Parempi ratkaisu on poistaa koko sarake taulusta:le:
id username---------- ----------1 uolevi2 maija3 liisa4 aapeli
Vaikka saraketta ei enää ole, voimme silti laskea ystävien määrän täten:
SELECT COUNT(*)FROM Users A, Friends KWHERE A.username='uolevi' AND k.user = A.id;
Normalisointi (Normalization)
Tietokannan teoriassa puhutaan usein termistä normalisointi (normalization), jonka avulla tietokannan rakennetta parannetaan. Tämä tapahtuu muuttamalla tietokannan rakennetta siten, että se vastaa tiettyjä normaalimuotoja (normal forms.
Käytännössä, normalisointi johtaa samoihin tuloksiin kuin yllä olevat periaatteet, mutta normaalimuotojen vaatimukset ovat hieman tulkinnanvaraiset. Jos haluat käyttää hieman aikaa tietokantojen teoriaan, kannattaa tutustua tarkemmin normaalimuotoihin. Muutoin yllä olevat periaatteet ovat melkoisen riittävät.
Tiedon kuvailu
Seuraavaksi käsittelemme kaksi tapaa kuvailla tietokannan rakennetta. Graafinen kuvaus näyttää tietokannan taulut, sarakkeet ja viitteet niiden välillä, kun taas SQL-skeema näyttää tietokannan luomiseen käytetyt SQL-komennot.
Tietokantakaavio (Database diagram)
Tietokantakaavio on graafinen esitys tietokannasta, jossa jokainen taulu on laatikko joka sisältää taulun nimen ja sarakkeet listana. Viittaukset rivien välillä näytetään yhteyksinä laatikoiden välillä.
Tietokantakaavion piirtämiseen on monia vähän erilaisia tapoja. Seuraava kaavio on luotu netissä olevalla työkalulla https://dbdiagram.io/:
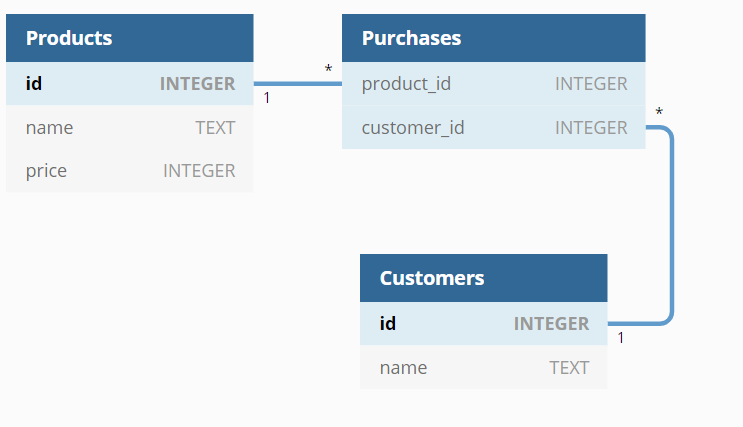
Tässä merkki 1 tarkoittaa, että sarakkeessa on eri arvo joka rivillä, ja merkki * puolestaan tarkoittaa, että sarakkeessa voi olla sama arvo usealla rivillä. Esimerkiksi taulussa Products jokaisella rivillä on eri id, mutta taulussa Purchases usealla rivillä voi olla sama product_id.
SQL-skeema (SQL schema)
SQL-skeema on tekstiesitys tietokannasta, joka antaa komennot joita tarvittiin tietokannan luomiseen. Hyvä puoli tässä esitysmuodossa on, että se on ehdottoman tarkka, ja voimme luoda tietokannan uudelleen niin halutessamme.
Esimerkiksi yllä olevan tietokannan skeema olisi seuraava:
CREATE TABLE Products (id INTEGER PRIMARY KEY, name TEXT, price INTEGER);CREATE TABLE Customers (id INTEGER PRIMARY KEY, name TEXT);CREATE TABLE Purchases (product_id INTEGER, customer_id INTEGER);
Oletetaan tämän skeeman olevan tiedostossa depiction.sql. Voimme luoda tietokannan SQLite-tulkilla komennolla .read:
sqlite> .read depiction.sqlsqlite> .tablesCustomers Purchases Products
Toisaalta voimme myös käyttää komentoa .schema SQLite-tulkissa, joka palauttaa tämänhetkisen skeeman:
sqlite> .schemaCREATE TABLE Products (id INTEGER PRIMARY KEY, name TEXT, price INTEGER);CREATE TABLE Customers (id INTEGER PRIMARY KEY, name TEXT);CREATE TABLE Purchases (product_id INTEGER, customer_id INTEGER);
Tietokannan muuttaminen
Käytännössä on epätavallista että tietokanta suunnitellaan ensin, ja että se pysyisi muuttumattomana maailmanloppuun asti. On paljon yleisempää, että tietokannan rakenne muuttuu silloin tällöin.
Muutosten tekeminen
Yksinkertainen muutos on uuden taulun lisääminen tietokantaan. Tässä tapauksessa voimme lisätä taulun komennolla CREATE TABLE kuten tavallisesti.
Voimme myös muokata olemassaolevan taulun rakennetta komennolla ALTER TABLE. Tällä komennolla on useita käyttötarkoituksia, riippuen siitä mitä haluamme tehdä. Voimme esimerkiksi lisätä sarakkeen komennolla ADD COLUMN.
Tarkastellaan taulua Customers:
id name----------- ----------1 Uolevi2 Maija3 Aapeli
Kun haluamme lisätä uuden sarakkeen address, voimme ajaa seuraavan komennon:
ALTER TABLE Customers ADD COLUMN address TEXT;
Tämän seurauksena taulumme näyttää tältä:
id name address----------- ---------- ----------1 Uolevi2 Maija3 Aapeli
Koska lisäsimme uuden sarakkeen, olemassaolevilla riveillä ei ole tietoa siinä sarakkeessa. Tietoa voidaan päivittää tämän jälkeen komennolla UPDATE.
Komennon ALTER TABLE käyttö riippuu tietokantajärjestelmästä, ja jälleen kerran tieto löytyy käytössä olevan järjestelmän dokumentaatiosta. SQLitessä komento on melko rajattu, verrattuna esimerkiksi PostgreSQL:ään.
Muutoksen haasteet
Olemassaolevan tietokannan muutoksissa on yksi ongelma: Tietokannassa on yleensä tietoja ja se on käytössä jossain sovelluksessa. Kuinka voimme toteuttaa muutokset siten, että ne eivät vaikuta järjestelmän toimivuuteen?
Taulun tai sarakkeen lisääminen ovat yleensä melko helppoja muutoksia, sillä ne eivät vaikuta tietokannan käyttämiseen vanhalla tavalla, mutta haastavampia muutoksia ovat esimerkiksi sarakkeen poistaminen tai uudelleenimeäminen.
Yksi hyvä periaate on tehdä muutokset vaiheittain, askel kerrallaan. Esimerkiksi, jos tarvitsee muuttaa sarakkeen nimeä, voit tehdä sen näin:
- Lisää uusi sarake vanhan sarakkeen rinnalle
- Muuta tietoa kirjoittavat SQL-komennot siten, että ne kirjoittavat sekä vanhaan että uuteen sarakkeeseen.
- Kopioi data vanhan sarakkeen riveiltä uuden sarakkeen vastaaviin.
- Muuta tietoa lukevat SQL-komennot siten, että ne lukevat uudesta sarakkeesta.
- Mutta tietoa kirjoittavat SQL-komennot siten, että ne kirjoittavat vain uuteen sarakkeeseen.
- Poista vanha sarake taulusta.
Tällä menetelmällä järjestelmä pystyy käyttämään tietokantaa koko ajan, ja tietokannan käyttäjät eivät huomaa muutosta. Prosessin lopuksi sarakkeen nimi on muutettu uudeksi.
Migraatio (Migration)
Termi migraatio voi tarkoittaa joko tietokannan rakenteen muuttamista tai tietokannan siirtämistä toiseen sijaintiin. Tämä on valitettavasti kurssimme tavoitteiden ulkopuolella..