

Multible tables
References and queries
The central idea about relational databases is, that a row in a table can rerefence to a row in another table. Thus we can form a query, which collects information from several tables, based on the references. In practice the reference is usually made to the id of the other table.
Example
Let's examine a situation, where a database has information about coursee and their teachers. We assume, that each course has only one teacher, and one teacher can teach several courses.
We save the information about teachers into the table Teachers. Each teacher has an id, which we can reference.
id name---------- ----------1 Ahonen2 Isohanni3 Niemi4 Laaksonen
In the table Courses we have the information about the courses and for each course we have a reference to the teacher.
id name teacher_id---------- ---------------- -----------1 Basic programming 32 More programming 13 Algorithms 14 Scrum masters 45 Algebra 3
We can now get the courses with their teacher with the following query, which searches information from both tables Courses and Teachers at the same time:
SELECT Courses.name, Teachers.nameFROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id;
As the query has multiple tables, we declare the tables for the columns. For example Courses.name refers to the column name for the table Courses.
The query returns information as follows:
name name------------------ ----------Basic programming NiemiMore programming AhonenAlgorithms AhonenScrum masters LaaksonenAlgebra Niemi
What actually happened here?
In the query above, compared to previous queries, we are using multiple tables (FROM Courses, Teachers), but what does it mean in practice?
The basic idea is, that when a query has several tables, the starting point of the query is all the possible combinations of all the rows in all the selected tables. After this we use WHERE to define, which of the combinations are we interested at.
A good way to understand the functionality with multiple tables is to first examine a query, which gets us all the columns and does not have a WHERE. In the example database above the search could be as follows:
SELECT * FROM Courses, Teachers;
Because we have 5 rows in table Courses and 4 rows in table Teachers, the result set of the query is 5 * 4 = 20 rows. The result set contains all the possible ways to first select a row from table Courses and then a row from table Teachers:
id name teacher_id id name---------- ------------------ ----------- ---------- ----------1 Basic programming 3 1 Ahonen1 Basic programming 3 2 Isohanni1 Basic programming 3 3 Niemi1 Basic programming 3 4 Laaksonen2 More programming 1 1 Ahonen2 More programming 1 2 Isohanni2 More programming 1 3 Niemi2 More programming 1 4 Laaksonen3 Algorithms 1 1 Ahonen3 Algorithms 1 2 Isohanni3 Algorithms 1 3 Niemi3 Algorithms 1 4 Laaksonen4 Scrum masters 4 1 Ahonen4 Scrum masters 4 2 Isohanni4 Scrum masters 4 3 Niemi4 Scrum masters 4 4 Laaksonen5 Algebra 3 1 Ahonen5 Algebra 3 2 Isohanni5 Algebra 3 3 Niemi5 Algebra 3 4 Laaksonen
Most of these result rows are not interesting how ever, as they are not connected to one another in any way. For example the first row of results tells us, that a course called Basic programming exists, and so does a teacher called Ahonen. For this we limit our search, so thaat the teacher's id has to match on both tables:
SELECT * FROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id;
With this change we get a more meaningful result:
id name teacher_id id name---------- ---------------- ----------- ---------- ----------1 Basic programming 3 3 Niemi2 More programming 1 1 Ahonen3 Algorithms 1 1 Ahonen4 Scrum masters 4 4 Laaksonen5 Algebra 3 3 Niemi
Now we can improve more by telling the columns we are interested in:
SELECT Courses.name, Teachers.nameFROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id;
And get the same result as earlier:
name name------------------ ----------Basic programming NiemiMore programming AhonenAlgorithms AhonenScrum masters LaaksonenAlgebra Niemi
More conditions in a query
In a query for multiple tables, the WHERE connects the rows of interest for us, but we can have more conditions with the WHERE just like before. For example we could do the following query:
SELECT Courses.name, Teachers.nameFROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id AND Teachers.name = 'Niemi';
Now we get all the courses taught by Niemi:
name name---------------- ----------Basic programming NiemiAlgebra Niemi
Short names for tables
We can concentrate our queries by giving the tables alternative shorter names, with which we can reference them in the query. For example the query
SELECT Courses.name, Teachers.nameFROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id;
Can be shortened into:
SELECT C.name, T.nameFROM Courses AS C, Teachers AS TWHERE C.teacher_id = T.id;
And as the AS is not compulsory, we can even do:
SELECT C.name, T.nameFROM Courses C, Teachers TWHERE C.teacher_id = T.id;
Repeating a table
In a query for multiple tables we can use the same table more than once, as long as they are given different names. For example, the following query returns all the possible combinations for choosing how to pair two teachers:
SELECT A.name, B.name FROM Teachers A, Teachers B;
Query returns as follows:
name name---------- ----------Ahonen AhonenAhonen IsohanniAhonen NiemiAhonen LaaksonenIsohanni AhonenIsohanni IsohanniIsohanni NiemiIsohanni LaaksonenNiemi AhonenNiemi IsohanniNiemi NiemiNiemi LaaksonenLaaksonen AhonenLaaksonen IsohanniLaaksonen NiemiLaaksonen Laaksonen
Junction table
There are usually two types of relations between tables:
- One-to-many relation: A row from Table A is connected to a maximum of one row in Table B. A row from Table B can be connected to many rows in Table A.
- Many-to-many relation: A row from Table A can be connected many rows in Table B. A row from Table B can be connected to many rows in Table A.
In the first case we can add a column to Table A which references to Table B, as we have previously done. In the second case the situation is more difficult, as a single reference in either table would not be sufficient. The solution is to create a third table, which contains the information about the references.
Example
Let's examine a situation, where a webshop has products and customers, and each customer has selected a certain amount of products into their shopping cart. A certain customer can have several products, and also same product can be in several customers' carts.
We will build our database so that it has three tables: Products, Customers and Purchases. The junction table Purchases identicates, which products are in which customer's shopping carts. Each row for it is a representation of a pair "customer X's cart contains product Y".
We assume our tables to have the following content:
Productsid name price-- ------ -----1 radish 72 carrot 53 turnip 44 parsley 85 celery 4Customersid name-- ------1 Uolevi2 Maija3 AapeliPurchasescustomer_id product_id----------- ----------1 21 52 12 42 5
Now we can get the customers and products like this:
SELECT C.name, P.nameFROM Customers C, Products P, Purchases OWHERE C.id = O.customer_id AND P.id = O.product_id;
The idea of the query is to get from tables `Customers and Products the information to match the table Purchases. To get reasonable results, we connect the tables with two conditions. We get the following result set with our query:
name name---------- ----------Uolevi carrotUolevi celeryMaija radishMaija parsleyMaija celery
With the same idea we could find out, which products are in the cart for a specific customer. For example, the following query retrieves the purchases for Maija:
SELECT P.nameFROM Customers C, Products P, Purchases OWHERE C.id = O.customer_id AND P.id = O.product_id AND C.name = 'Maija';
name----------radishparsleycelery
Aggregate from tables
We can use aggregate functions and groupings for queries with multiple tables as well. For example we can create an aggregate, which shows for each customer how many products they have in their shopping cart, and what is the total price. We can do it as follows:
SELECT C.name, COUNT(P.id), SUM(P.price)FROM Customers C, Products P, Purchases OWHERE C.id = O.customer_id AND P.id = O.product_idGROUP BY C.id;
How are we grouping?
In this query the grouping is done by the column C.id, but in the query we are searching with the column C.name. This is reasonable, as the column C.id dictates the column C.name, and the query works fine in SQLite.
In other databases (such as PostgreSQL) the requirement might be, that the column we are searching as such should also be in the grouping. Then the grouping should be GROUP BY C.id, C.name
The idea of this query is to group the rows by the customer's id, when the function COUNT(P.id) gives the amount of products in the customer's cart and the function SUM(P.price) gives the total amount for said products. Our result set is as follows:
name COUNT(P.id) SUM(P.price)---------- ----------- ------------Uolevi 2 9Maija 3 19
This means, that Uolevi's purchases contain 2 products, with combined price of 9. Maija on the other hand has 3 products with the combined price of 19. Everything looks good... Or does it?
The problem with our query is that is is missing our third customer, Aapeli. We have come across a problem, which we shall sort by the end of this part.
JOIN syntax
So far we have gottern information from tables by selectin our tables with FROM, which usually works fine. However, sometimes we need to use the alternative JOIN syntax. It is useful when the result set seems to be "missing" information.
Ways of Query
Next we have two ways of doing the same query, first by the way we already know, and the by using JOIN syntax.
SELECT Courses.name, Teachers.nameFROM Courses, TeachersWHERE Courses.teacher_id = Teachers.id;SELECT Courses.name, Teachers.nameFROM Courses JOIN Teachers ON Courses.teacher_id = Teachers.id;
In the latter JOIN syntax, we use the word JOIN between the tables as well as a condition to connect the rows with ON. After this we could use WHERE to add more conditions, just like before.
In this case JOIN syntax is just an alternative way to perform the query and it brings nothing new. Let's see next, how we can expand the syntax so, that it gives us new possibilities in our queries.
Missing information problem
Let's have a look at a situation, where we have the example tables of Courses and Teachers, but one course is missing a teacher:
id name teacher_id---------- ---------------- -----------1 Basic programming 32 More programming 13 Algorithms 14 Scrum masters5 Algebra 3
On row 4 column teacher_id the value is NULL, so if we do either of the queries from before, the row 4 does not match any of the rows for table Teachers. Because of this the result set does not contain the row for Scrum masters:
name name------------------ ----------Basic programming NiemiMore programming AhonenAlgorithms AhonenAlgebra Niemi
Solution to this problem is to use LEFT JOIN syntax. This means that if a row from the left table does not connect to any row on the right table, the row is still included in the result set. For that row the values based on the right table is NULL.
In our case we could do the query like this:
SELECT Courses.name, Teachers.nameFROM Courses LEFT JOIN Teachers ON Courses.teacher_id = Teachers.id;
Now we get the course Scrum masters without a teacher:
name name------------------ ----------Basic programming NiemiMore programming AhonenAlgorithms AhonenScrum mastersAlgebra Niemi
JOIN query family
JOIN query has four variations:
JOIN: Works just as a regular query joining two tables.LEFT JOIN: If the row from the left table does not connect to the right table, it is still chosen to be part of the result set.RIGHT JOIN: If the row from the right table does not connect to the left table, it is still chosen to be part of the result set.FULL JOIN: From both left and right table we separately add into the result set those rows, which do not connect to the other table.
For SQLite we can only do the first two ones. Fortunately, LEFT JOIN is the most common one (at least on this course, anyways).
A Venn diagram representation would be something like this:
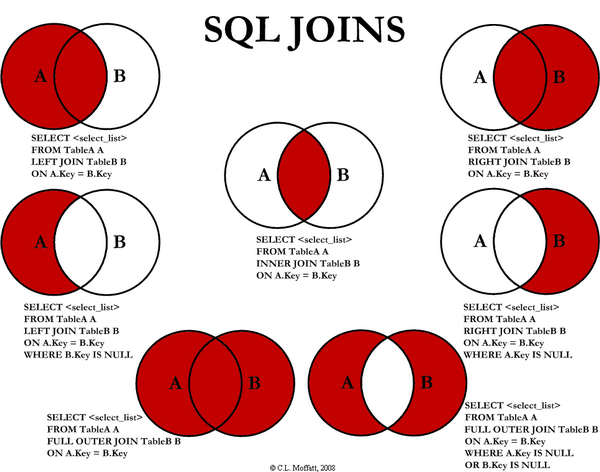
This diagram contains more than four variations. INNER JOIN is equal to JOIN, and FULL OUTER JOIN is FULL JOIN. The other variations are exclusive alternatives for the queries.
Missing information in aggregate query
Now we can tackle the problem of missing Aapeli. In our database we have the following tables:
Productsid name price-- ------ -----1 radish 72 carrot 53 turnip 44 parsley 85 celery 4Customersid name-- ------1 Uolevi2 Maija3 AapeliPurchasescustomer_id product_id----------- ----------1 21 52 12 42 5
We declared our aggregate of purchases with the following query:
SELECT C.name, COUNT(P.id), SUM(P.price)FROM Customers C, Products P, Purchases OWHERE C.id = O.customer_id AND P.id = O.product_idGROUP BY C.id;
We ended up missing Aapeli from our result set:
name COUNT(P.id) SUM(P.price)---------- ----------- ------------Uolevi 2 9Maija 3 19
The cause for our problem is that Aapeli does not have any purchases, so when the query selects combinations from rows, there are no such rows where Aapeli would be present. The solution is to use LEFT JOIN like this:
SELECT C.name, COUNT(P.id), SUM(P.price)FROM Customers C LEFT JOIN Purchases OON C.id = O.customer_idLEFT JOIN Products PON P.id = O.product_idGROUP BY C.id;
Now we also get Aapeli into our results:
name COUNT(P.id) SUM(P.price)---------- ----------- ------------Uolevi 2 9Maija 3 19Aapeli 0
As Aapeli has no purchases, the sum of the prices is NULL.