

Designing databases
Design principles
When designing a database we have to decide, which tables the database has and which columns each table has. To do this there are multiple possibilities, but by knowing a few principles and with common sense you can get surprisingly far.
A good goal for designing is that the resulting database is comfortable to use with SQL. The database structure should be such, that we can read and update data easily with SQL commands.
Here are four principles for desiging a database:
Principle 1
The tables and their columns in the database are fixed, and the database user only makes changes to the rows. All the rows containing similar data are in the same table.
Principle 2
Each column contains a singular data, such as an integer or a string, but not a list of information. A list is saved into its own table so that each element is a row of its own.
Principle 3
Each information is exactly once in the database. Elsewhere the information is a referenced by the primary key.
Principle 4
The database does not contain information, which can be calculated or deducted from other information content in the database.
Example
Let's look at a situation, where a web site has users and each user has a list of friends. Here we can see quite poorly designed table Users, which contains information about users and their friends:
id username friends total---------- ---------- ------------ ----------1 uolevi maija,liisa 22 maija aapeli 13 liisa 04 aapeli uolevi,maija 2
In this table the idea is, that the column friends contains a list of friends as a string, where the usernames for friends are separated with a comma. Also, in the column total we are given the amount of friends in total a user has.
With this structure we are breaking the principles 2-4, but now we have a chance to evolve the database and think, what the principles are based on.
Improvement 1
The database breaks the principle 2, since the column friends has a list of friends. The problem with this kind of column is, that it is hard to handle with SQL commands. For example how can we find out, who all have added Maija as their friend?
The solution is to remove the column friends and rather create a new table Friends, where each row is a friendship in the form of "user x has user y on their friend list":
user friend---------- ----------uolevi maijauolevi liisamaija aapeliaapeli uoleviaapeli maija
Now the table Users looks like this:
id username total---------- ---------- ----------1 uolevi 22 maija 13 liisa 04 aapeli 2
Now we can easily solve, on whose lists Maija is:
SELECT user FROM Friends WHERE friend='maija';
Improvement 2
The new table Friends is nice, but it breaks the principle 3, as the usernames are now in multiple places. The problem here is, that if the username changes, we have to search all the places where the username is used.
The resolution is to change the table Friends so that it uses references. Now the table looks like this:
user_id friend_id----------- ----------1 21 32 44 14 2
Notice, this makes it more difficult to find on whose lists Maija is, as we have to get the usernames from table Users:
SELECT A.usernameFROM Users A, Users B, Friends KWHERE A.id = K.user_id AND B.id = K.friend_id AND B.username = 'maija';
Despite this the change is reasonable, as now the usernames are only used once, in the table Users.
Improvement 3
The database is still breaking the principle 4, as the column total can be calculated from the table Friends. It is quite a handy column, as we can get for example Uolevi's friends like this:
SELECT total FROM Users WHERE username='uolevi';
The problem is though, that every time we change friends, we would have to update the column total. A better solution is to remove the column from the table:
id username---------- ----------1 uolevi2 maija3 liisa4 aapeli
Even though the column does not exist anymore, we can still count the amount of friends like this:
SELECT COUNT(*)FROM Users A, Friends KWHERE A.username='uolevi' AND k.user = A.id;
Normalisation
In the theory of database is often used the term normalization, which is used to make the structure of a database better. This is done by altering the database in such a way, that it implements certain normal forms.
In practice, normalization leads to the same result as the principles above, but the requirements for normal forms are a bit vague. If you want to spend some time with database theory, you might delve deeper into normal forms. Otherwise the principles above are quite sufficient.
Depicting structure
Next we shall handle two ways to depict database structure. A graphical database diagram shows the database tables, columns and the references between them, whereas SQL schema shows the SQL commands used to create the tables.
Database diagram
A database diagram is a graphical representation of a database, where every table is a box containing the name of the table and the columns as a list. The refences between the rows are shown as connections between the boxes.
There are several tools to draw database diagrams. This picture was done with an online tool https://dbdiagram.io/:
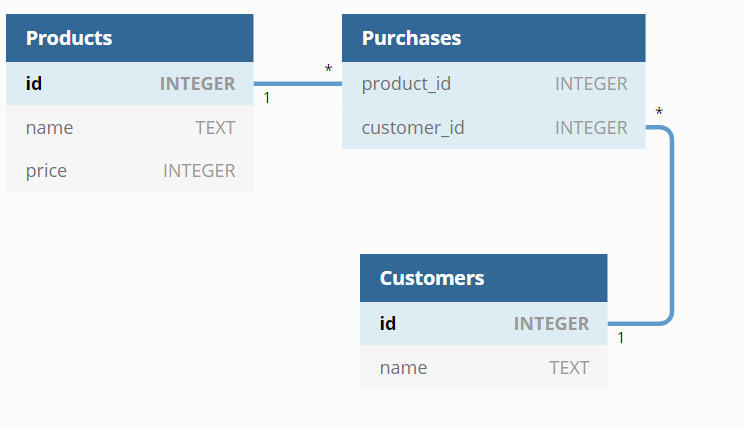
Here the notation 1 means that the columns has a different value for each row, and the notation * means that the column can have the same value on multiple rows. For example in the table Products each row has different id, but in the table Purchases multiple rows can have the same product_id.
SQL schema
A SQL Schema is a text representation of the database, where we give the commands needed to create the database. The advantage of this form is that it is definately accurate, and we can recreate the database with it if wanted.
For example the schema for the database above would be as follows:
CREATE TABLE Products (id INTEGER PRIMARY KEY, name TEXT, price INTEGER);CREATE TABLE Customers (id INTEGER PRIMARY KEY, name TEXT);CREATE TABLE Purchases (product_id INTEGER, customer_id INTEGER);
If we assume this schema to be in a file depiction.sql. we can create the database with the SQLite interpreter with the command .read:
sqlite> .read depiction.sqlsqlite> .tablesCustomers Purchases Products
On the other hand we can also use the command .schema in the SQLite interpreter, which returns the current schema:
sqlite> .schemaCREATE TABLE Products (id INTEGER PRIMARY KEY, name TEXT, price INTEGER);CREATE TABLE Customers (id INTEGER PRIMARY KEY, name TEXT);CREATE TABLE Purchases (product_id INTEGER, customer_id INTEGER);
Changing database
In practice it is unusual that the database is designed first and then it stays unchanged until the end of times. It is much more common for the database structure to change every now and then.
Performing the changes
A simple alteration is adding a new table to the database. In this case we can create the table with the command CREATE TABLE as usual.
We can also change structure of an existing table with the command ALTER TABLE. This command has multiple uses, depending on what we want to do. For example we can add a column to the table with the command ADD COLUMN.
Let's look at the table Customers:
id name----------- ----------1 Uolevi2 Maija3 Aapeli
When we want to add a new column address, we can run the following command:
ALTER TABLE Customers ADD COLUMN address TEXT;
This results with our table looking like this:
id name address----------- ---------- ----------1 Uolevi2 Maija3 Aapeli
Since we added a new column, existing rows do not contain any information in that column. The data can be changed after this with the UPDATE command.
The usage of ALTER TABLE depends on the database system, and once again more information can be found from the database system documentation. In SQLite the command is quite limited, compared to for example PostgreSQL.
Challenges in alterations
Changing the structure of an existing database has one problem: The database usually has information and it is being used in some application. How can we implement the changes so, that they do not interfere the functionality of the system?
Adding a table or a column are usually quite easy changes, since they do not affect using the database in the old way, but more difficult changes are for example removing or changing the name of a column.
One good principle is to do changes gradually, or step by step. For example, if you have to change the name of a column, you can do it like this:
- Add a new column alongside the old column
- Change the SQL commands writing the data so, that they save the data to both old and new column.
- Copy the data from the rows of the old column to the new one.
- Change the SQL commands reading the data so, that they read from the new column.
- Change the SQL commands writing the data so, that they save the data to only the new column.
- Remove the old column from the table.
With this procedure the system can use the database the whole time, and the system user does not notice the change. At the end of the process the name of the column has been changed to a new one.
Migration
The term migration can mean either changing the structure of a database or moving the database information to another location. This is beyond the scope of this course, unfortunately.